Pipeline pattern
 Bronislav Klučka, Aug 22, 2025, 04:43 PM
Bronislav Klučka, Aug 22, 2025, 04:43 PM
In my last article I discussed the rules engine pattern, a pattern motivated by separation of concerns, high cohesion, and low coupling. Today, we will continue with another pattern that supports these principles: pipeline
Let's start with two examples.
Example 1
The task is to open a CSV file with orders, filter orders for specific products, and send these orders via API to a service that processes orders.
Pseudo-implementation
function uploadOrders() {
const file = fileSystem.open('./file.csv');
while (const row = fileSystem.readCSV(file)) {
if (row[3] === 'item1') {
const customer = customerService.get(row[0]);
const price = priceService.get(row[2]);
const data = {
name: customer.lastName + ' ' + customer.firstName,
count: row[1],
unitPrice: price.value,
id: row[3],
}
net.post('https://company.com/api/order', { body: data });
}
}
fileSystem.close(file);
}The code looks fine, it's reasonably short, but try to imagine that the functionality will grow: what if there are more sources, not just CSV; what if there are more conditions, what if the API format becomes more complex. And at some point, the code may become unreadable.
Example 2
The task will be to authenticate and authorize requests to the API.
Pseudo-implementace
function authRequest() {
const headers = request.headersAsMap();
let user = null;
if (headers.authorization && headers.authorization.startsWith('Bearer ')) {
user = authModule.getUserByAuthzToken(headers.authorization); // returns User | null
}
if (user === null) throw Error('...')
const allowedRoutes = routesModule.getValidRoutesForUser(user);
if (!allowedRoutes[request.method] || !allowedRoutes[request.method].includes(request.path)) {
throw Error('...')
}
let data = url.parseQuery(request.queryParams) ?? {};
data = merge(data, JSON.parse(request.body));
if (!validateApiRequest(request.method, request.path, data)) {
throw Error('...')
}
return {
user,
data
}
}What if we have more authentication methods, or they become more complex? What if we modify the authorization logic to a complex system of rights? Even this example is pushing the limits...
Pipeline
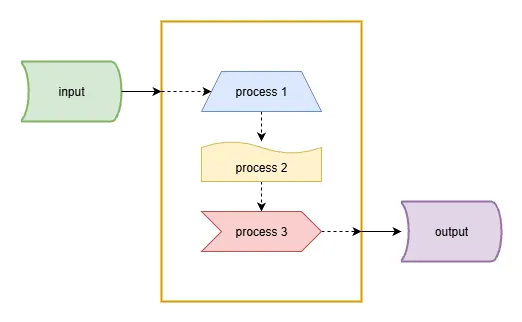
A pipeline is a pattern that divides a sequence of processes into individual steps and orchestrates them. Instead of one large process, the pipeline pattern consists of several independent subprocesses that are unaware of each other, and it is up to the parent process, the orchestrator, to execute them in the required order.
Basic features:
sequential data processing
depends on the order of steps
Example 1
interface Order {
customerId: string;
priceId: string;
count: number;
itemId: string;
}
interface ApiOrder {
name: string;
price: number;
count: number;
id: string;
}
function getOrders(): Order[] {
const file = fileSystem.open('./file.csv');
const result: Order[] = [];
while (const row = fileSystem.readCSV(file)) {
result.push({
customerId: row[0];
count: row[1];
priceId: row[2];
itemId: row[3];
})
}
fileSystem.close(file);
return result;
}
function filterOrder(order: Order): boolean {
return order.itemId === 'item1';
}
function transformOrder(order: Order): ApiOrder {
const customer = customerService.get(order.customerId);
const price = priceService.get(order.priceId);
return {
name: customer.lastName + ' ' + customer.firstName,
count: order.count,
unitPrice: price.value,
id: order.itemId,
}
}
function sendOrder(order: ApiOrder): boolean {
return net.post('https://company.com/api/order', { body: order });
}
// now, let's have fun
function processAllOrders1() {
getOrders()
.filter(filterOrder)
.map(transformOrder)
.map(sendOrder);
}
/**
* but what if getOrders() would return million records? how about memory consumption?
* generator to the rescue
*/
function* getOrders2(): Generator<Order[]> {
const file = fileSystem.open('./file.csv');
while (const row = fileSystem.readCSV(file)) {
yield {
customerId: row[0];
count: row[1];
priceId: row[2];
itemId: row[3];
}
}
fileSystem.close(file);
}
function processAllOrders2() {
// build iterator
const iter = getOrders2()
.filter(filterOrder)
.map(transformOrder)
.map(sendOrder)
// run it
let result = iterator.next();
while (!result.done) {
result = iterator.next();
}
}
Suddenly, if we have a different source of orders, the only thing we will change is the source of orders without affecting anything else, etc.
Example 2
interface Context {
user: User | null;
routeAuthorized: boolean;
data: object | null;
}
function authnUser(request: Request, context: Context): void {
const headers = request.headersAsMap();
if (headers.authorization && headers.authorization.startsWith('Bearer ')) {
context.user = authModule.getUserByAuthzToken(headers.authorization); // returns User | null
}
}
function authzUser(request: Request, context: Context): void {
if (context.user !== null) {
const allowedRoutes = routesModule.getValidRoutesForUser(context.user);
context.routeAuthorized = allowedRoutes[request.method] && allowedRoutes[request.method].includes(request.path)
}
}
function requestData(request: Request, context: Context): void {
if (context.routeAuthorized) {
let data = url.parseQuery(request.queryParams) ?? {};
data = merge(data, JSON.parse(request.body));
if (validateApiRequest(request.method, request.path, data)) {
context.data = data
}
}
}
function authRequest(): Context {
const result = {
user: null;
routeAuthorized: false;
data: null;
}
authnUser(request, result);
if (result.user === null) throw Error('...');
authzUser(request, result);
if (result.routeAuthorized === false) throw Error('...');
requestData(request, result);
return result;
}Clear division of responsibilities, easy expandability.
What can you use the pipeline pattern for?
ETL / SFT processes
applying filters/transformations to data, e.g. images
compiler - tokenization, parsing, compilation, assembly, linking
interpreter - tokenization, parsing, execution
staging - a complex process in several stages in several modules (e.g., order processing - payment, warehouse, shipping, notification)
CI/CD pipeline
And many more.